
.svg)
Virtusizeにコンピュータービジョンが必要なのはなぜか?
オンラインで衣服を購入するときに思い通りのサイズを選択するのは難しいです。 Virtusizeの大きな目標は、このサイズ選びを容易にすることであり、機械学習はそれを達成する上で大きな役割を果たします。
機械学習の1つの分野として、コンピュータービジョンがあります。コンピュータービジョンには、とりわけ画像認識が含まれており、ファッションテクノロジー分野では、特に有用なツールです。製品カテゴリで絞り込みをするような単純な作業であっても、それが例えばパンツやスカートであっても、製品ページによっては難しい場合があります。そのような場合、製品カテゴリが何であるかを知るために画像認識が必要です。
上記の他には、光学式文字認識(OCR)を使用し、pdf上にある表から製品の数値情報を抽出するような使用方法もあります。さらに、製品の説明にはその製品のカテゴリ情報がないことが多いので、画像認識は製品のスタイルやフィット感を予測するために大規模に使用できる唯一の方法となります。このセーターはカーディガンなのか、それともプルオーバーなのか?このスカートはタイトかフレアか?このような質問は、さまざまなカテゴリの違いを知るために、数千の画像上にあるモデルを読み込み、学習した後にやっとわかるようなものです。
画像認識とはなにか?
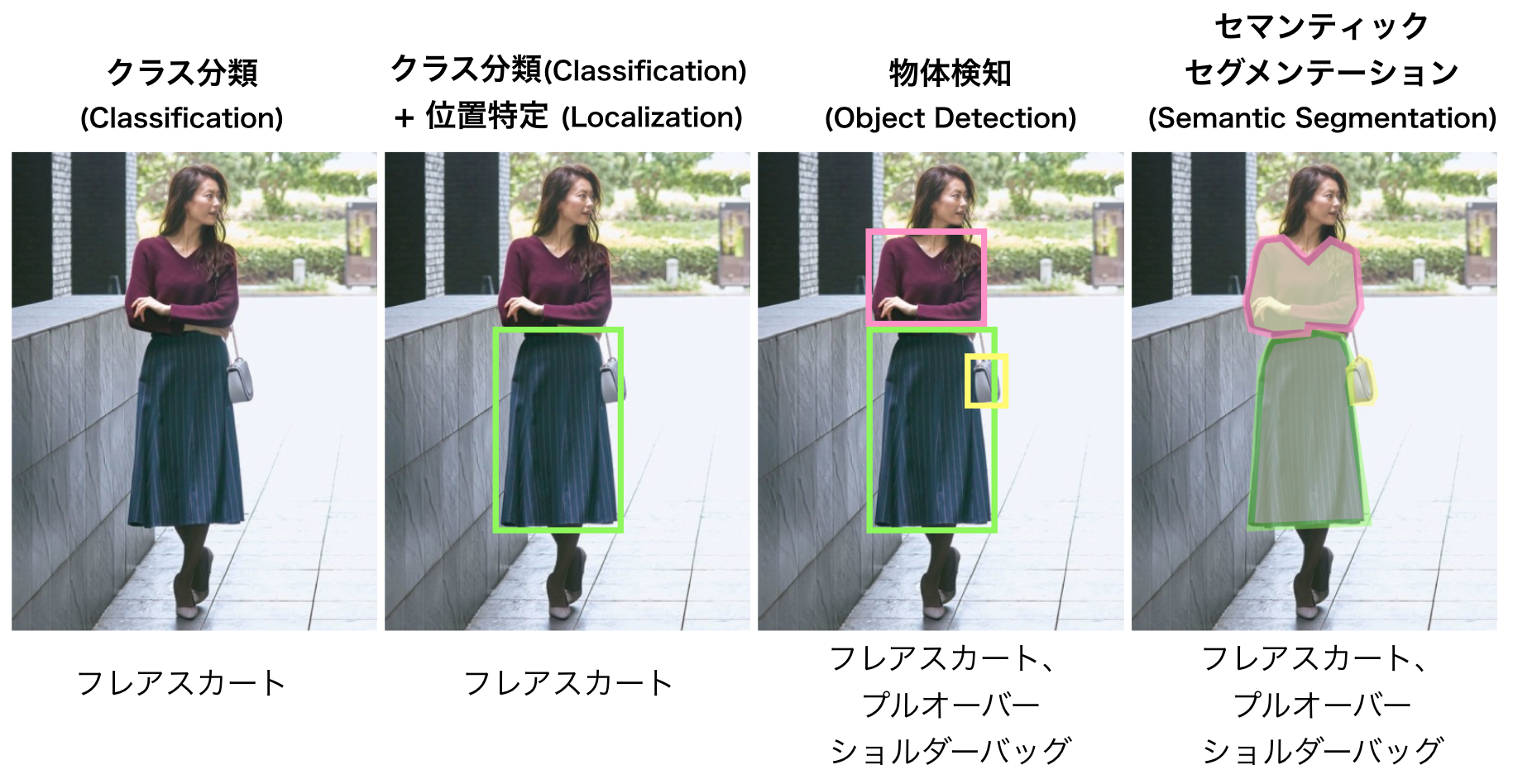
図1に示すように、画像認識にはいくつかの種類があります。最も単純なものは分類をすることであり、モデルが単一のラベルを画像に割り当てるときです。 タイトスカートとフレアスカートの違いを伝えるようモデルが学習している場合、画像を受信すると、「フレア」と出力します。分類およびローカリゼーションモデルは、分類する前に対象のアイテムの周りに境界ボックスをつくります。これは、特に画像内に様々な商品がある場合に有効です。
複数のオブジェクトを認識する必要がある場合は、オブジェクト検出が最適です。一致する可能性のあるカテゴリのリスト内のすべてのオブジェクトは、境界ボックスとラベルを取得します。 オブジェクトの形状を知る必要がある作業の場合、セマンティックまたはインスタンスのセグメンテーションが必要です。セマンティックセグメンテーションは、各カテゴリをユニットとして認識し、インスタンスセグメンテーションは、クラス内の各オブジェクトに個別の形状を与えます。
転移学習とはなにか?
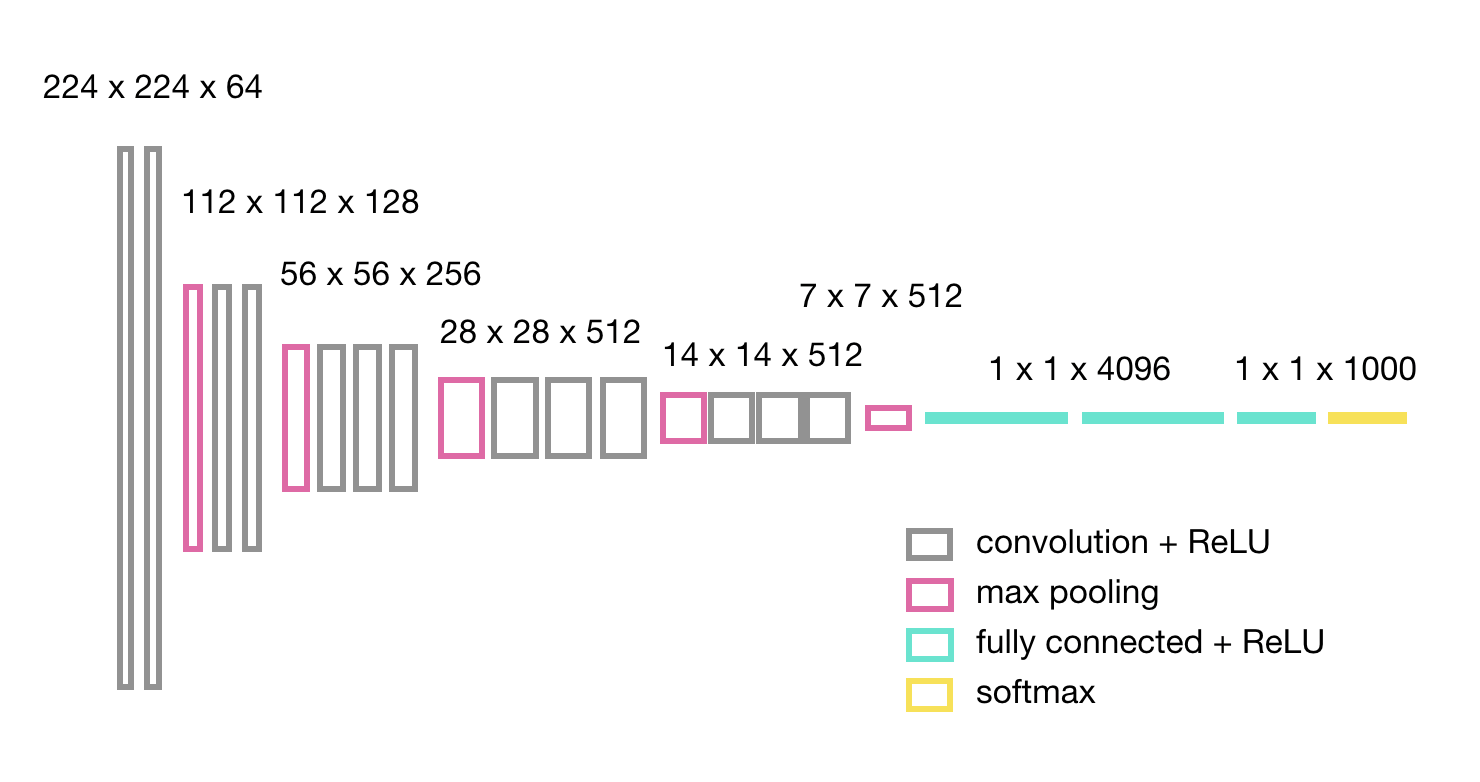
画像分類モデルは、多くの画像とそれらを学習するための多くの時間を必要とします。たとえば、2014年に提案されたよく知られたVGG16[1]と呼ばれる畳み込みニューラルネットワークモデルは、1,000のカテゴリに属する1,400万枚の画像の学習に2週間以上かかりました。各カテゴリに数千の画像がなく、GPU(計算能力)にアクセスできない場合、転移学習は良い解決方法となります。例として、図2に示すVGG16のアーキテクチャを見てみましょう。フレアスカートとタイトスカートを予測するモデルの場合、最も簡単なことは、1,000次元のベクトルを出力する最後のレイヤーを2次元ベクトルを出力するレイヤーに置き換えることです。そして、他のすべてのレイヤーの重みを固定したまま、最後のレイヤーのみを再学習させる必要があります。
もし正確な結果が得られない場合は、他のレイヤーを再学習させている間に、最初の複数レイヤーの重みを修正できます。このようにして、モデルは、画像のある特性を特定しながらも、基本的な形状や生地を認識するための何百万もの画像から学んだことを記憶します。 1つのアーキテクチャが望ましい精度を達成できない場合、他のアーキテクチャをいつでも試すことができます。最近では、Inception、ResNet、MobileNet、DenseNetなど、事前学習済みモデルが多数あります。

画像認識は製品改善にどのように役立つのか?
次に、Virtusizeユーザーの顧客体験向上にコンピュータービジョンがどのように役立つかを示す例をいくつか提示します。多くの場合、オンラインストアはあらゆる種類のジャケットを1つのカテゴリにまとめます。たとえば、分厚い冬のジャケットは、薄手の革ジャケットと同じカテゴリに分類されます。また、服の下に着用する衣類かどうかを認識していない場合、サイズレのおすすめは難しくなります。画像認識モデルに「プロテクティブ」ジャケットというラベルを付けると、シャツやセーターの上に着用されることが前提となるため、その商品のサイズ感には余裕があるべきだとわかります。
この意図したフィット感を目指す考えは、あらゆる種類の衣服に適用されます。図4に示すように、スタイルによってトップスはきつすぎたり、ゆるすぎたりすることがあります。商品の意図したフィット感を知る唯一の方法はその画像を見ることであり、それを大規模に行う唯一の方法はコンピュータービジョンを利用することです。あるシャツがぴったりとしたサイズ感であるべきと認識することで、大きすぎるサイズをおすすめすることを防ぎます。これらは、Virtusizeのコンピュータービジョンのいくつかのアプリケーションのほんの一部です。 この投稿が画像認識とファッションテクノロジーにおけるその可能性の良いご紹介をなることを願っています。

参考資料
Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks For
Large-Scale Image Recognition. https://arxiv.org/pdf/1409.1556.pdf
Virtusizeにコンピュータービジョンが必要なのはなぜか?
オンラインで衣服を購入するときに思い通りのサイズを選択するのは難しいです。 Virtusizeの大きな目標は、このサイズ選びを容易にすることであり、機械学習はそれを達成する上で大きな役割を果たします。
機械学習の1つの分野として、コンピュータービジョンがあります。コンピュータービジョンには、とりわけ画像認識が含まれており、ファッションテクノロジー分野では、特に有用なツールです。製品カテゴリで絞り込みをするような単純な作業であっても、それが例えばパンツやスカートであっても、製品ページによっては難しい場合があります。そのような場合、製品カテゴリが何であるかを知るために画像認識が必要です。
上記の他には、光学式文字認識(OCR)を使用し、pdf上にある表から製品の数値情報を抽出するような使用方法もあります。さらに、製品の説明にはその製品のカテゴリ情報がないことが多いので、画像認識は製品のスタイルやフィット感を予測するために大規模に使用できる唯一の方法となります。このセーターはカーディガンなのか、それともプルオーバーなのか?このスカートはタイトかフレアか?このような質問は、さまざまなカテゴリの違いを知るために、数千の画像上にあるモデルを読み込み、学習した後にやっとわかるようなものです。
画像認識とはなにか?
図1に示すように、画像認識にはいくつかの種類があります。最も単純なものは分類をすることであり、モデルが単一のラベルを画像に割り当てるときです。 タイトスカートとフレアスカートの違いを伝えるようモデルが学習している場合、画像を受信すると、「フレア」と出力します。分類およびローカリゼーションモデルは、分類する前に対象のアイテムの周りに境界ボックスをつくります。これは、特に画像内に様々な商品がある場合に有効です。
複数のオブジェクトを認識する必要がある場合は、オブジェクト検出が最適です。一致する可能性のあるカテゴリのリスト内のすべてのオブジェクトは、境界ボックスとラベルを取得します。 オブジェクトの形状を知る必要がある作業の場合、セマンティックまたはインスタンスのセグメンテーションが必要です。セマンティックセグメンテーションは、各カテゴリをユニットとして認識し、インスタンスセグメンテーションは、クラス内の各オブジェクトに個別の形状を与えます。
転移学習とはなにか?
画像分類モデルは、多くの画像とそれらを学習するための多くの時間を必要とします。たとえば、2014年に提案されたよく知られたVGG16[1]と呼ばれる畳み込みニューラルネットワークモデルは、1,000のカテゴリに属する1,400万枚の画像の学習に2週間以上かかりました。各カテゴリに数千の画像がなく、GPU(計算能力)にアクセスできない場合、転移学習は良い解決方法となります。例として、図2に示すVGG16のアーキテクチャを見てみましょう。フレアスカートとタイトスカートを予測するモデルの場合、最も簡単なことは、1,000次元のベクトルを出力する最後のレイヤーを2次元ベクトルを出力するレイヤーに置き換えることです。そして、他のすべてのレイヤーの重みを固定したまま、最後のレイヤーのみを再学習させる必要があります。
もし正確な結果が得られない場合は、他のレイヤーを再学習させている間に、最初の複数レイヤーの重みを修正できます。このようにして、モデルは、画像のある特性を特定しながらも、基本的な形状や生地を認識するための何百万もの画像から学んだことを記憶します。 1つのアーキテクチャが望ましい精度を達成できない場合、他のアーキテクチャをいつでも試すことができます。最近では、Inception、ResNet、MobileNet、DenseNetなど、事前学習済みモデルが多数あります。
画像認識は製品改善にどのように役立つのか?
次に、Virtusizeユーザーの顧客体験向上にコンピュータービジョンがどのように役立つかを示す例をいくつか提示します。多くの場合、オンラインストアはあらゆる種類のジャケットを1つのカテゴリにまとめます。たとえば、分厚い冬のジャケットは、薄手の革ジャケットと同じカテゴリに分類されます。また、服の下に着用する衣類かどうかを認識していない場合、サイズレのおすすめは難しくなります。画像認識モデルに「プロテクティブ」ジャケットというラベルを付けると、シャツやセーターの上に着用されることが前提となるため、その商品のサイズ感には余裕があるべきだとわかります。
この意図したフィット感を目指す考えは、あらゆる種類の衣服に適用されます。図4に示すように、スタイルによってトップスはきつすぎたり、ゆるすぎたりすることがあります。商品の意図したフィット感を知る唯一の方法はその画像を見ることであり、それを大規模に行う唯一の方法はコンピュータービジョンを利用することです。あるシャツがぴったりとしたサイズ感であるべきと認識することで、大きすぎるサイズをおすすめすることを防ぎます。これらは、Virtusizeのコンピュータービジョンのいくつかのアプリケーションのほんの一部です。 この投稿が画像認識とファッションテクノロジーにおけるその可能性の良いご紹介をなることを願っています。
参考資料
Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks For
Large-Scale Image Recognition. https://arxiv.org/pdf/1409.1556.pdf
Virtusizeにコンピュータービジョンが必要なのはなぜか?
オンラインで衣服を購入するときに思い通りのサイズを選択するのは難しいです。 Virtusizeの大きな目標は、このサイズ選びを容易にすることであり、機械学習はそれを達成する上で大きな役割を果たします。
機械学習の1つの分野として、コンピュータービジョンがあります。コンピュータービジョンには、とりわけ画像認識が含まれており、ファッションテクノロジー分野では、特に有用なツールです。製品カテゴリで絞り込みをするような単純な作業であっても、それが例えばパンツやスカートであっても、製品ページによっては難しい場合があります。そのような場合、製品カテゴリが何であるかを知るために画像認識が必要です。
上記の他には、光学式文字認識(OCR)を使用し、pdf上にある表から製品の数値情報を抽出するような使用方法もあります。さらに、製品の説明にはその製品のカテゴリ情報がないことが多いので、画像認識は製品のスタイルやフィット感を予測するために大規模に使用できる唯一の方法となります。このセーターはカーディガンなのか、それともプルオーバーなのか?このスカートはタイトかフレアか?このような質問は、さまざまなカテゴリの違いを知るために、数千の画像上にあるモデルを読み込み、学習した後にやっとわかるようなものです。
画像認識とはなにか?
図1に示すように、画像認識にはいくつかの種類があります。最も単純なものは分類をすることであり、モデルが単一のラベルを画像に割り当てるときです。 タイトスカートとフレアスカートの違いを伝えるようモデルが学習している場合、画像を受信すると、「フレア」と出力します。分類およびローカリゼーションモデルは、分類する前に対象のアイテムの周りに境界ボックスをつくります。これは、特に画像内に様々な商品がある場合に有効です。
複数のオブジェクトを認識する必要がある場合は、オブジェクト検出が最適です。一致する可能性のあるカテゴリのリスト内のすべてのオブジェクトは、境界ボックスとラベルを取得します。 オブジェクトの形状を知る必要がある作業の場合、セマンティックまたはインスタンスのセグメンテーションが必要です。セマンティックセグメンテーションは、各カテゴリをユニットとして認識し、インスタンスセグメンテーションは、クラス内の各オブジェクトに個別の形状を与えます。
転移学習とはなにか?
画像分類モデルは、多くの画像とそれらを学習するための多くの時間を必要とします。たとえば、2014年に提案されたよく知られたVGG16[1]と呼ばれる畳み込みニューラルネットワークモデルは、1,000のカテゴリに属する1,400万枚の画像の学習に2週間以上かかりました。各カテゴリに数千の画像がなく、GPU(計算能力)にアクセスできない場合、転移学習は良い解決方法となります。例として、図2に示すVGG16のアーキテクチャを見てみましょう。フレアスカートとタイトスカートを予測するモデルの場合、最も簡単なことは、1,000次元のベクトルを出力する最後のレイヤーを2次元ベクトルを出力するレイヤーに置き換えることです。そして、他のすべてのレイヤーの重みを固定したまま、最後のレイヤーのみを再学習させる必要があります。
もし正確な結果が得られない場合は、他のレイヤーを再学習させている間に、最初の複数レイヤーの重みを修正できます。このようにして、モデルは、画像のある特性を特定しながらも、基本的な形状や生地を認識するための何百万もの画像から学んだことを記憶します。 1つのアーキテクチャが望ましい精度を達成できない場合、他のアーキテクチャをいつでも試すことができます。最近では、Inception、ResNet、MobileNet、DenseNetなど、事前学習済みモデルが多数あります。
画像認識は製品改善にどのように役立つのか?
次に、Virtusizeユーザーの顧客体験向上にコンピュータービジョンがどのように役立つかを示す例をいくつか提示します。多くの場合、オンラインストアはあらゆる種類のジャケットを1つのカテゴリにまとめます。たとえば、分厚い冬のジャケットは、薄手の革ジャケットと同じカテゴリに分類されます。また、服の下に着用する衣類かどうかを認識していない場合、サイズレのおすすめは難しくなります。画像認識モデルに「プロテクティブ」ジャケットというラベルを付けると、シャツやセーターの上に着用されることが前提となるため、その商品のサイズ感には余裕があるべきだとわかります。
この意図したフィット感を目指す考えは、あらゆる種類の衣服に適用されます。図4に示すように、スタイルによってトップスはきつすぎたり、ゆるすぎたりすることがあります。商品の意図したフィット感を知る唯一の方法はその画像を見ることであり、それを大規模に行う唯一の方法はコンピュータービジョンを利用することです。あるシャツがぴったりとしたサイズ感であるべきと認識することで、大きすぎるサイズをおすすめすることを防ぎます。これらは、Virtusizeのコンピュータービジョンのいくつかのアプリケーションのほんの一部です。 この投稿が画像認識とファッションテクノロジーにおけるその可能性の良いご紹介をなることを願っています。
参考資料
Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks For
Large-Scale Image Recognition. https://arxiv.org/pdf/1409.1556.pdf
